[논문리뷰] REVE : A Foundation Model for EEG Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects
REVE : A Foundation Model for EEG Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects
https://arxiv.org/abs/2510.21585
💭 3줄 요약
- REVE(Representation for EEG with Versatile Embeddings)는 EEG 데이터의 이질성 문제에 대응하고 다양한 설정에 적응하도록 설계된 Foundation Model
- REVE는 임의의 길이와 전극 배열을 처리하는 4D positional encoding과 masked autoencoding objective를 활용하여 25,000명의 피험자로부터 얻은 60,000시간 이상의 EEG 데이터로 사전 학습
- REVE는 10가지 다운스트림 EEG task에서 state-of-the-art 성능을 달성하였고, 특히 linear probing에서 높은 일반화 능력을 보이며 표준화된 EEG 연구의 기반을 제공
👿 문제 상황 (Problem Statement)
전극 배치, 길이가 달라도 여러 EEG를 동일한 모델로 다루고 싶다
기존의 EEG foundation 모델은 특정 데이터셋, 특정 채널구성에 묶여있기에 이를 해결하기 위해 저자들은 REVE를 제시하였다.
⭐️ 핵심 Intuition & Idea
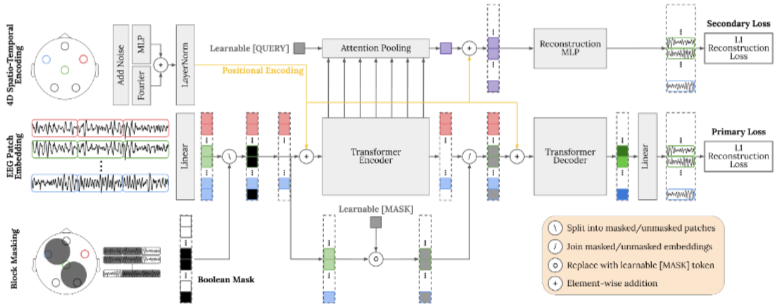
4D Positional Encoding
코드 : https://github.com/braindecode/braindecode/blob/master/braindecode/models/reve.py
기존 EEG 모델들은 특정 시간축 길이나, 고정된 전극 채널을 활용해야 하는 문제점이 존재하였다.
- 기존 모델들은 TUH 데이터베이스의 19, 21개의 고정 전극 채널을 활용한 pos. encoding을 진행하였고, 새로운 데이터(다른 채널 수)가 들어오면 fine-tuning은 필수적이었다.
REVE에서는 이러한 문제점 해결을 위해 전극의 3D 좌표 (x, y, z)와 시간 정보 (t)를 결합한 4D Positional Encoding (이하 4D PE)을 제안하였다.
1. 4D Coordinate 생성
EEG가 가지고 있는 (x, y, z) 좌표에 시간축 (t, 패치 단위, t = [1..P])을 결합하여 4D Coordinate 생성
- x, y, z : 실제 EEG의 전극 좌표를 활용하며, 일반화를 위해 가우시안 노이즈()를 추가
- t : 신호 패칭 후 각 패치의 idx를 1..P까지 할당
각 패치 단위 (x, y, z는 전극 위치라 전체 시간 동안 고정, t만 달라짐)로 [x, y, z, t] 4D Coordinate 생성
\[P_{ext} \in \mathbb{R}^{C \times p \times 4}\]2. 4D Fourier-Based Position Encoding
Défossez et al. (2023)
주파수 성분들의 데카르트 곱(Cartesian Product) 구조를 활용. 각 차원 [x, y, z, t] 에 대해 $n_{freq}$개의 주파수를 사용하며, 모든 조합으로 만든 벡터의 차원은 $n_{freq}^4$이 되고, 이를 사인, 코사인 변환을 거쳐 $2{\cdot}n_{freq}^4$개의 벡터를 생성
\[F_{pe} = [\sin(\omega_j \cdot v), \cos(\omega_j \cdot v)] \\ v \in \{x, y, z, t\}\]📍Decoding speech perception from non-invasive brain recordings
Défossez et al. (2023)
https://www.nature.com/articles/s42256-023-00714-5
센서 위치를 2D로 두고, 그 위에서 푸리에 기저로 ‘공간 함수’를 만듦
- 3D 센서 위치 → 2D 투영 후 [0, 1]로 스케일링
[0, 1] x [0, 1]
https://www.researchgate.net/figure/A-digital-image-is-a-2D-array-of-pixels-Each-pixel-is-characterised-by-its-x-y_fig1_221918148
- $a_j(x,y)$의 좌표를 푸리에 변환 $cos(2π(kx+ly)), sin(2π(kx+ly))$ 의 조합으로 $a_j$를 만듬($K$는 주파수 개수)
- 센서 $i$개의 좌표 $(x_i, y_i)$에서 $a_j(x_i, y_i)$로 평가한 값을 softmax에 넣어 위치 기반 attention 가중치로 센서를 재가중합
3. 학습 가능한 구성 요소 추가
푸리에 변환 후 MLP 적용
\[F_{lin} = \text{LayerNorm}(\text{GELU}(\text{Linear}(P_{ext})))\]4. 위치 인코딩 생성
\[P_{enc} = \text{LayerNorm}(F_{pe} + F_{lin})\]5. 원시 신호에 위치 인코딩
\[\text{최종 입력 토큰} = \underbrace{E_{signal}}_{\text{신호 모양}} + \underbrace{P_{enc}}_{\text{시공간 위치}}\]$E_{signal}$은 원시 신호를 $LinearProj.$한 벡터
📌 상세 개념 및 아이디어 (Key Concepts)
1.1. Block Masking : Spatio-Temporal Block Masking
Random masking을 하면 너무 쉬운 문제가 된다. 따라서 REVE는 Spatio-Temporal Block Masking을 사용하여 인접한 채널, 근처 시간 구간들을 통째로 가림
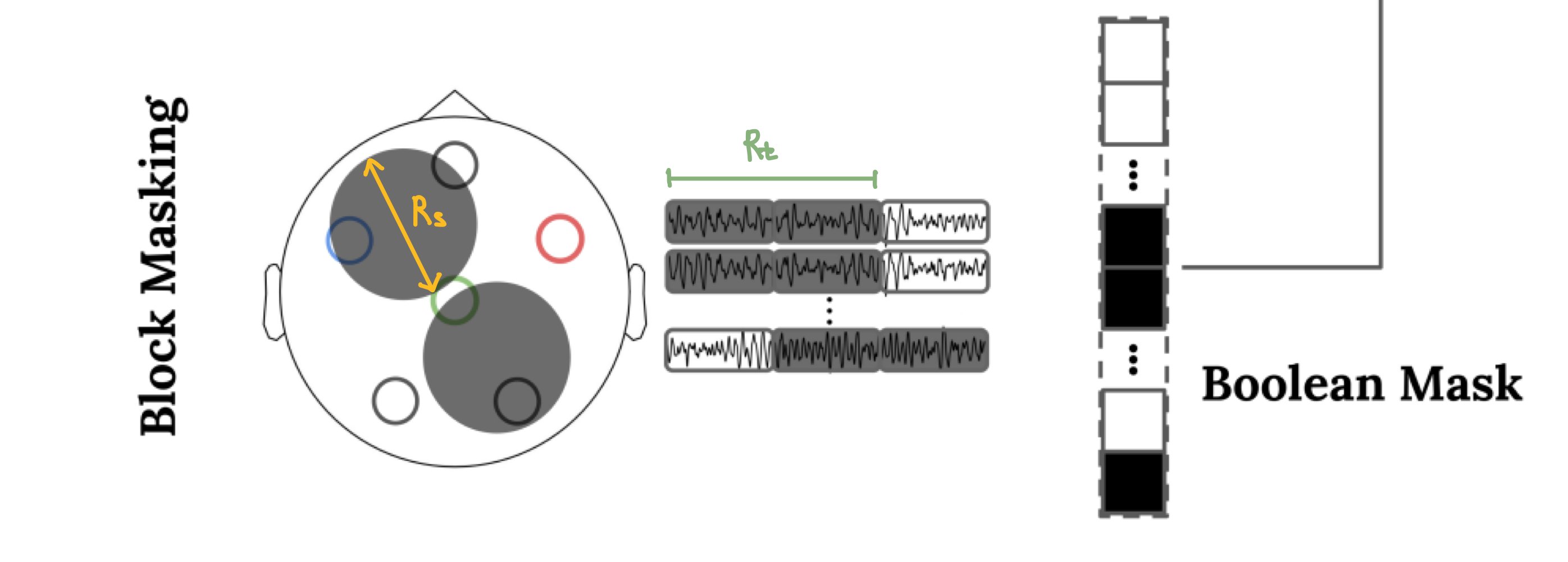
$M_r$ : 마스킹 비율
$R_s$ : 공간 마스킹 반경
$R_t$ : 시간 마스킹 반경
1.2. Dropout
Dropout 또한 Block Masking과 비슷한 접근을 가져간다. Dropout은 Channel 단위로 발생하며, 다른 모델들과 다른 점은 Spatio-Temporal Block Masking과 비슷하게 인접한 채널까지 Dropout을 적용한다는 점이다
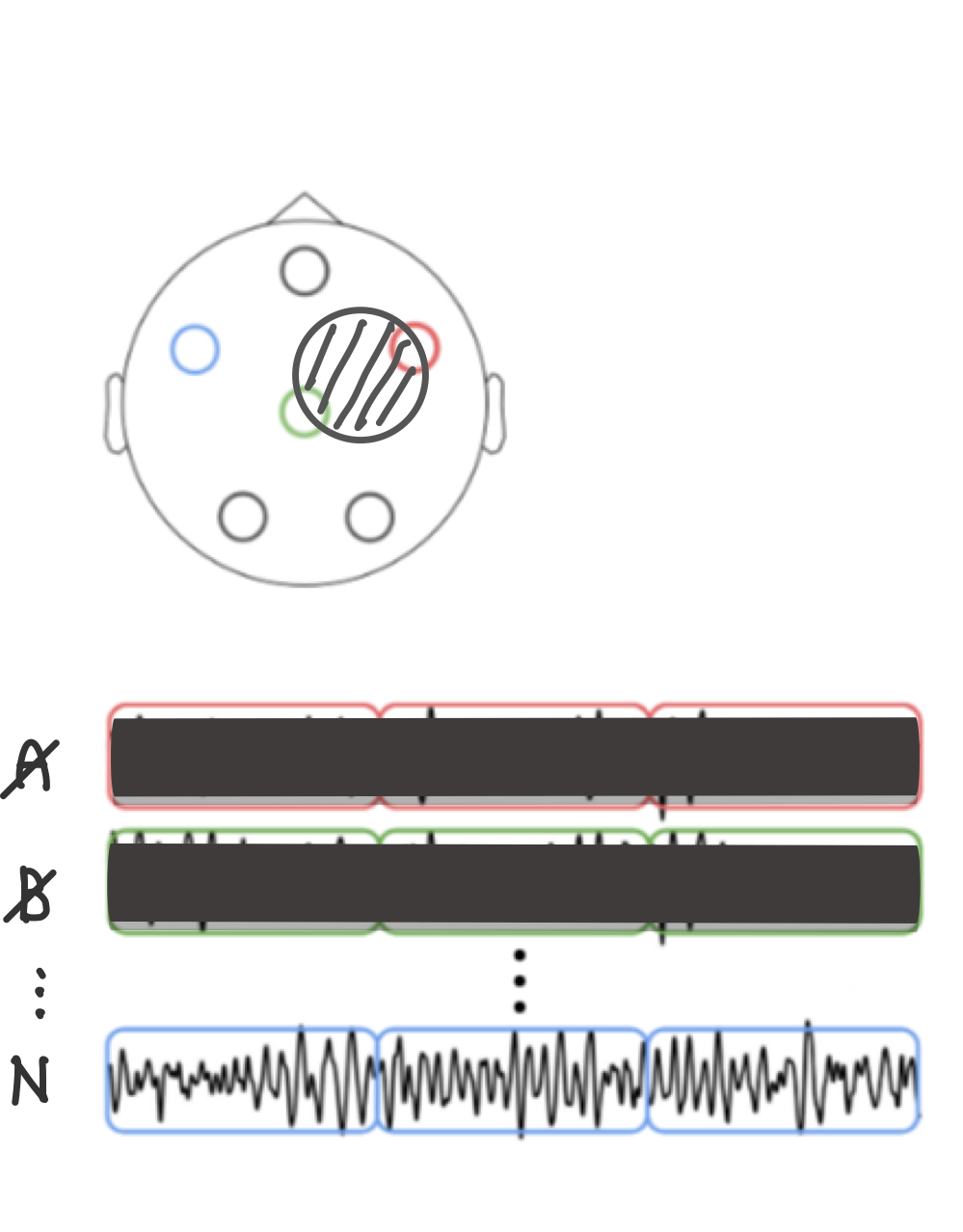
$D_r$ : Dropout 비율
$R_d$ : Dropout의 영향을 받을 인접한 공간 반경
2. Multi-Task Learning
2.1. Main Task
보이는걸 최대한 활용해서 마스킹을 복원해봐
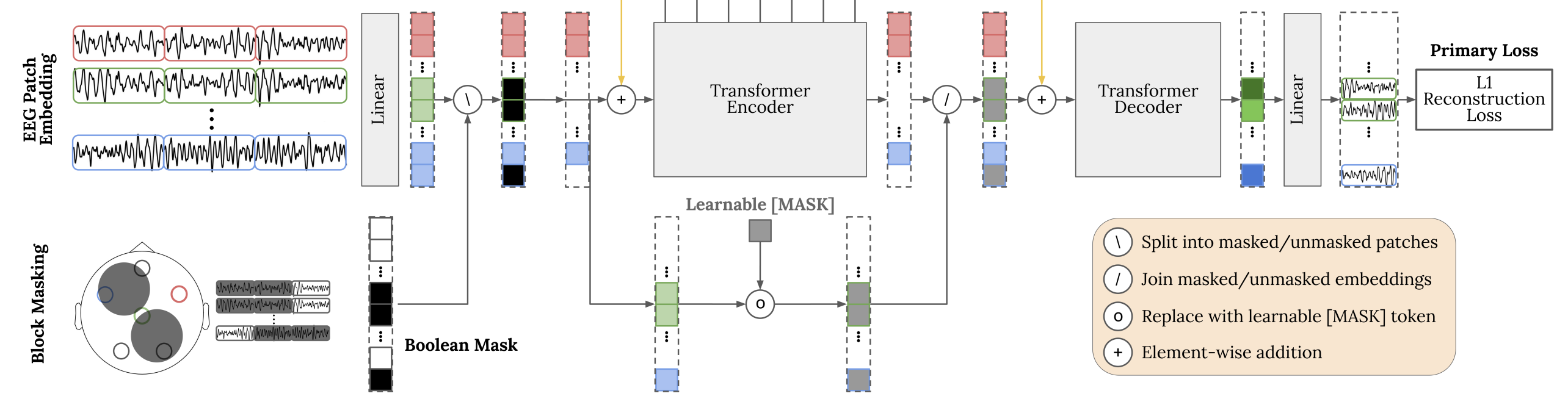
Spatio-Temporal Masking을 진행 후
- Encoder : Masking되지 않은 Visible Patch만 인코더에 들어감, 이는 계산 효율성을 위한 조치임
- Learnable Mask Token : 하지만 디코더는 원래의 전체 EEG를 재구성 시켜야하는데, 마스킹되어 사라진부분을 인코더에서 처리하지 않으므로, 마스킹된 부분이 어디인지, 그 크기가 어느정도 인지를 알아야 함
- 마스킹된 위치 개수 $N_m$만큼 학습 가능한 공유 벡터를 복제하여 배치함
- Decoder : Encoder의 output과 Learnable Mask Token을 합쳐 Decoder에 들어가게됨(이때 시공간적 위치를 알려주기 위해 4D Pos. Encoding이 더해짐) $\text{Decoder Input} = [\text{Encoded Features} + \text{Positional Encodings}] \cup [\text{Learnable Mask Tokens} + \text{Positional Encodings}]$
Learnable인 이유
EEG는 그 자체가 노이즈가 많은 데이터이고, 학습 과정에서 토큰을 통해 평균적인 EEG 신호의 잠재적 형태를 제시하기 위한 Prior임
Main Loss : L1
\[L_{\text{primary}} = \frac{1}{|P_m|} \sum_{i \in P_m} \| \hat{P}^{(i)}_m - P^{(i)}_m \|_1\]L2 말고 L1을 선택한 이유: EEG의 경우 노이즈가 많은 데이터이고, L2의 경우 이상치에 민감하므로 노이즈를 증폭시킬 위험이 있음
2.2. Secondary Task
Local 정보 없이 전체 내용을 잘 요약해서 복원해봐
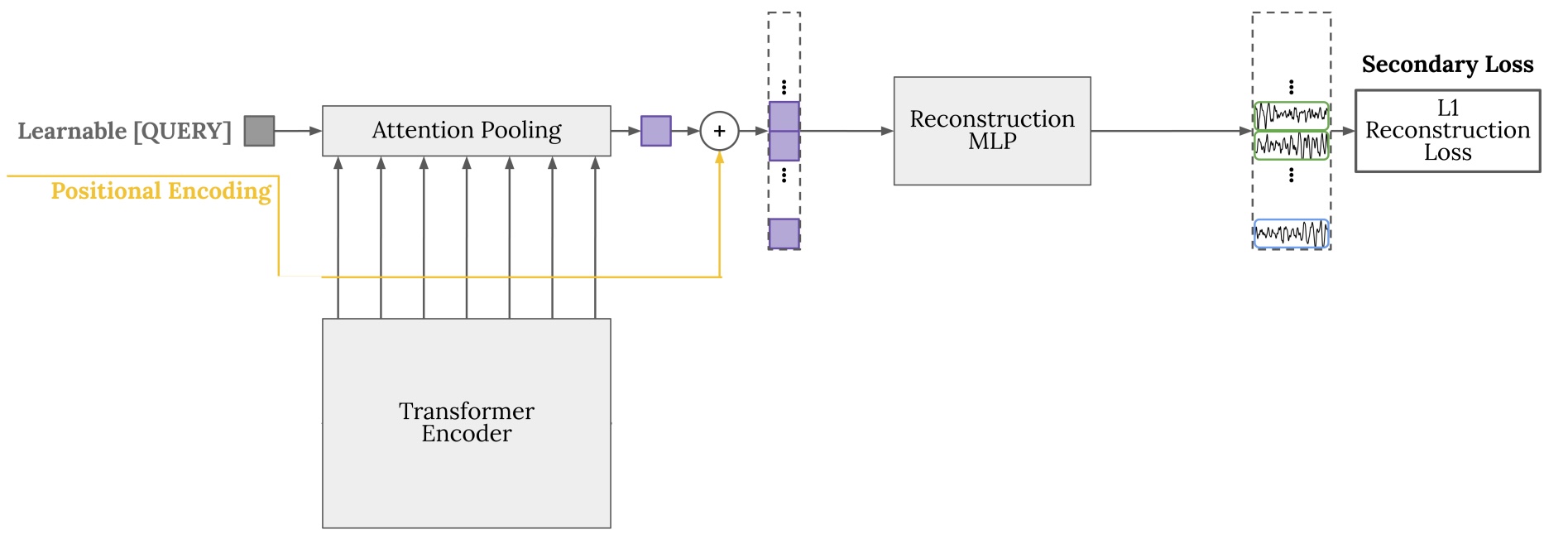
- Encoder의 Multi-Head Attention 레이어에서 나오는 모든 출력 토큰을 수집
- Learnable Query Token을 추가하여 수집된 모든 레이어들의 토큰들에 대해 Attention을 수행하여 모든 시공간 패치 정보를 가지고 있는 하나의 Global Token으로 압축
- 이 Global Token을 다시 확장(Global Token값을 복제)한 후 Positional Encoding을 더해준다
- 마지막으로 2-layer FFN을 진행하여 Masked Patch를 복원하는 Secondary Task를 진행한다.
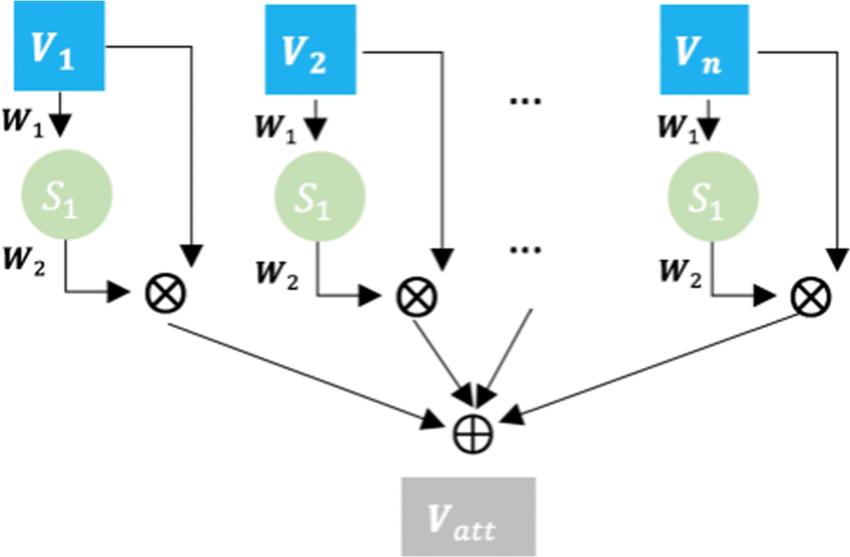
📍 Attention Pooling
여러 토큰을 하나의 요약 벡터로 압축하는 방법
어떤 토큰이 더 중요한지 attention으로 가중치를 줘서 모음
https://www.researchgate.net/figure/Overview-of-Attention-Pooling-Mechanism_fig2_330348603
Secondary Loss : L1
\[L_{\text{primary}} = \frac{1}{|P_m|} \sum_{i \in P_m} \| \hat{P}^{(i)}_m - P^{(i)}_m \|_1\]2.3. Loss
\[\text{Total Loss} = L_{\text{primary}} + \lambda \cdot L_{\text{secondary}}\]왜?
좋은 표현을 만드는 Encoder만을 남겨 비교적 Local에 집중하는 main task뿐만 아니라, secondary task를 통해서 Global한 요약을 강제한다. 이를 통해 Frozen/Linear Probing의 성능을 향상시킨다.
3. Transformer
대형 모델에서 검증 완료된, 변형된 Transformer를 채택
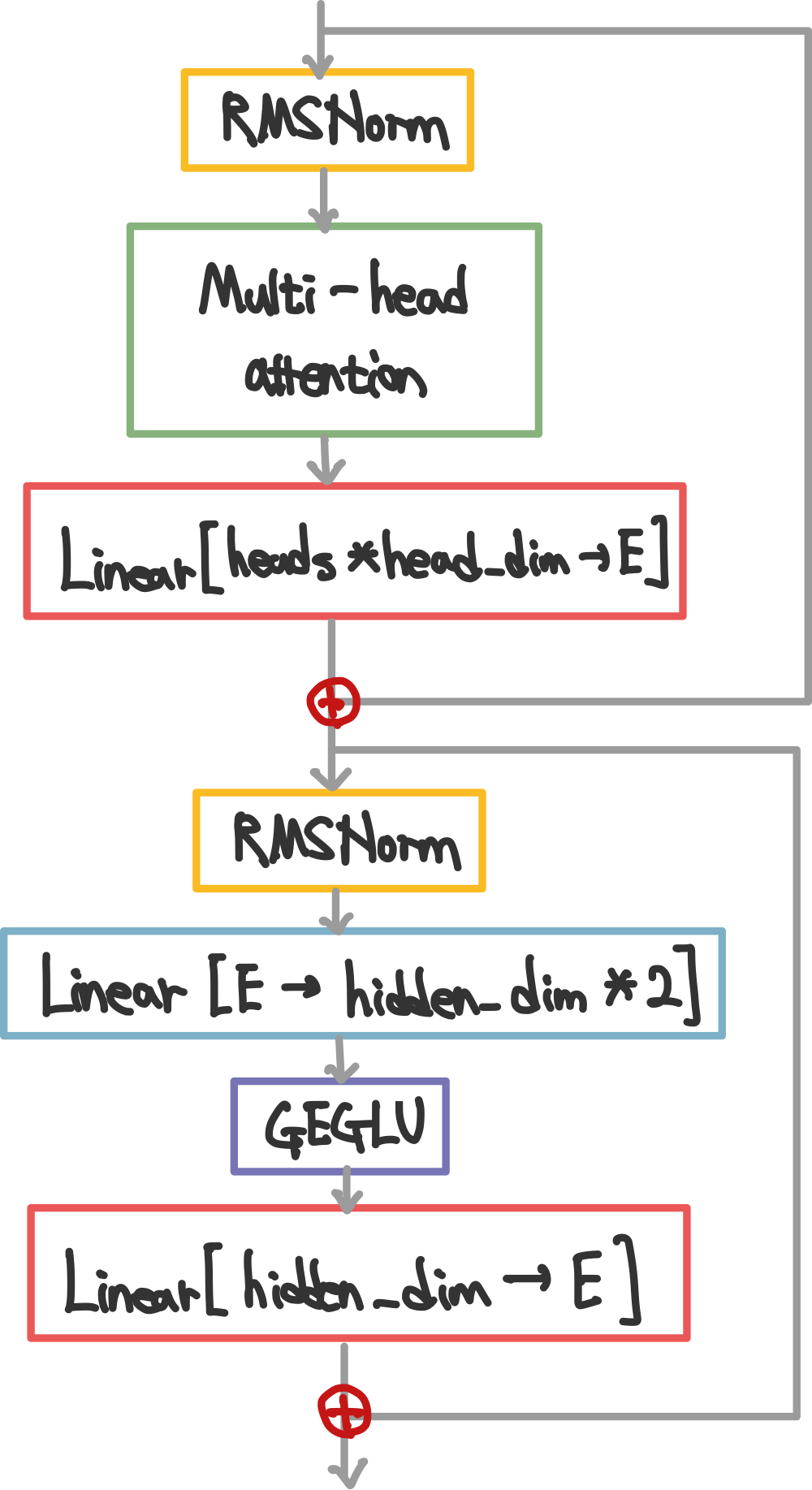
📍 RMSNorm
LayerNorm에서 변경됨
평균을 빼는 과정 없이 scale만 맞추는 방식에 가까움LayerNorm : 평균과 분산을 모두 맞춤
\(\begin{align*} \mu &= \frac{1}{d} \sum_{i=1}^{d} x_i \\ \sigma^2 &= \frac{1}{d} \sum_{i=1}^{d} (x_i - \mu)^2 \\ \bar{x}_i &= \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \\ y_i &= \gamma_i \bar{x}_i + \beta_i \end{align*}\)RMSNorm : scale(크기)만 안정화, 계산이 더 단순해지고 대규모 transformer에서 학습 안정성이 높아짐 \(\begin{align*} \text{RMS}(x) &= \sqrt{\frac{1}{d} \sum_{i=1}^{d} x_i^2 + \epsilon} \\ \bar{x}_i &= \frac{x_i}{\text{RMS}(x)} \\ y_i &= \gamma_i \bar{x}_i \end{align*}\)
📍 GEGLU
\[\begin{align*} \text{GELU}(x) &= x \cdot \Phi(x) \\ \Phi(x) &\approx 0.5x \left( 1 + \tanh \left( \sqrt{\frac{2}{\pi}} (x + 0.044715x^3) \right) \right) \end{align*}\]
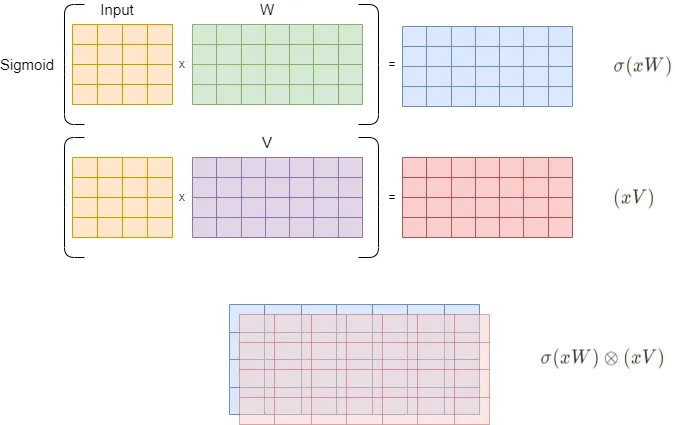
GELU(값이 크면 통과, 애매하면 조금만 통과)에서 변경됨 GEGLU는 GLU계열 activation으로 Sigmoid대신 GELU로 변경하여 단순 활성화가 아니라, 한 쪽이 다른쪽을 gate하는 구조로 입력 정보 중 어떤 부분을 더 살릴지 gate가 결정함, 이를 통해 표현력의 상승과 종종 GELU보다 성능이 상승하기도 함(transformer FFN에서)\[\begin{align*} \text{GEGLU}(x, W, V) &= \text{GELU}(xW) \otimes (xV) \end{align*}\]
https://docs.pytorch.org/docs/stable/generated/torch.nn.GELU.html
https://medium.com/@tariqanwarph/activation-function-and-glu-variants-for-transformer-models-a4fcbe85323f
📍Flash Attention v2
attention 수식은 크게 변경되지 않음, 하지만 중간 메모리 사용을 줄이고 병렬성을 개선해서 훨씬 효율적으로 계산이 가능함
긴 시퀀스, GPU 메모리 관리, 속도 측면에서 기존 attention보다 유리하다.
추가사항
Optimizer : StableAdamW
대규모 모델, mixed precision, large batch의 학습에서 덜 흔들리게 만든 버전
Scheduler : WarmUpStableDecay
초반 10%: linear warmup
그 다음 80%: peak LR 유지
마지막: 최대값의 1%까지 linear decay
📈 핵심 실험 결과 (Key Findings)
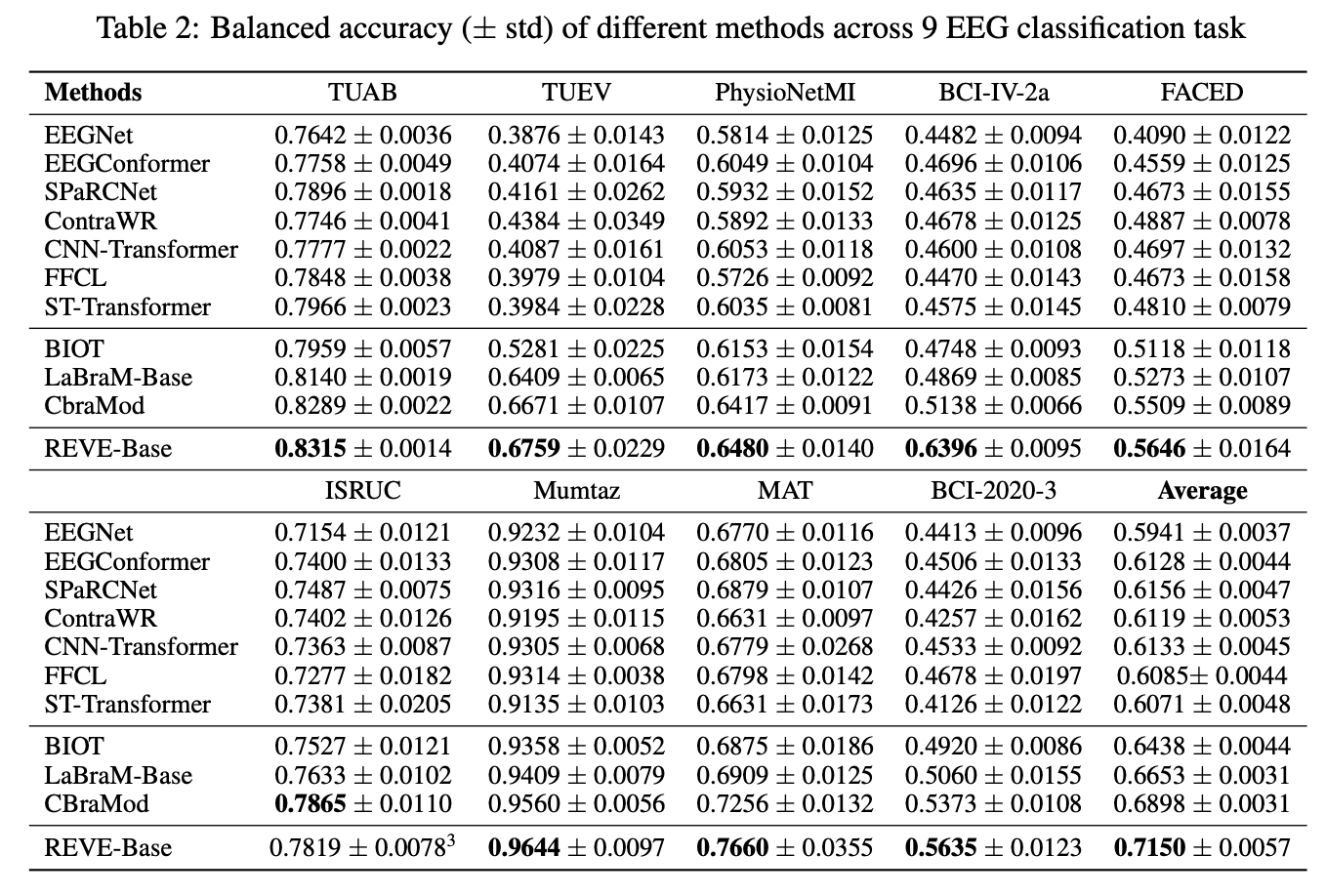
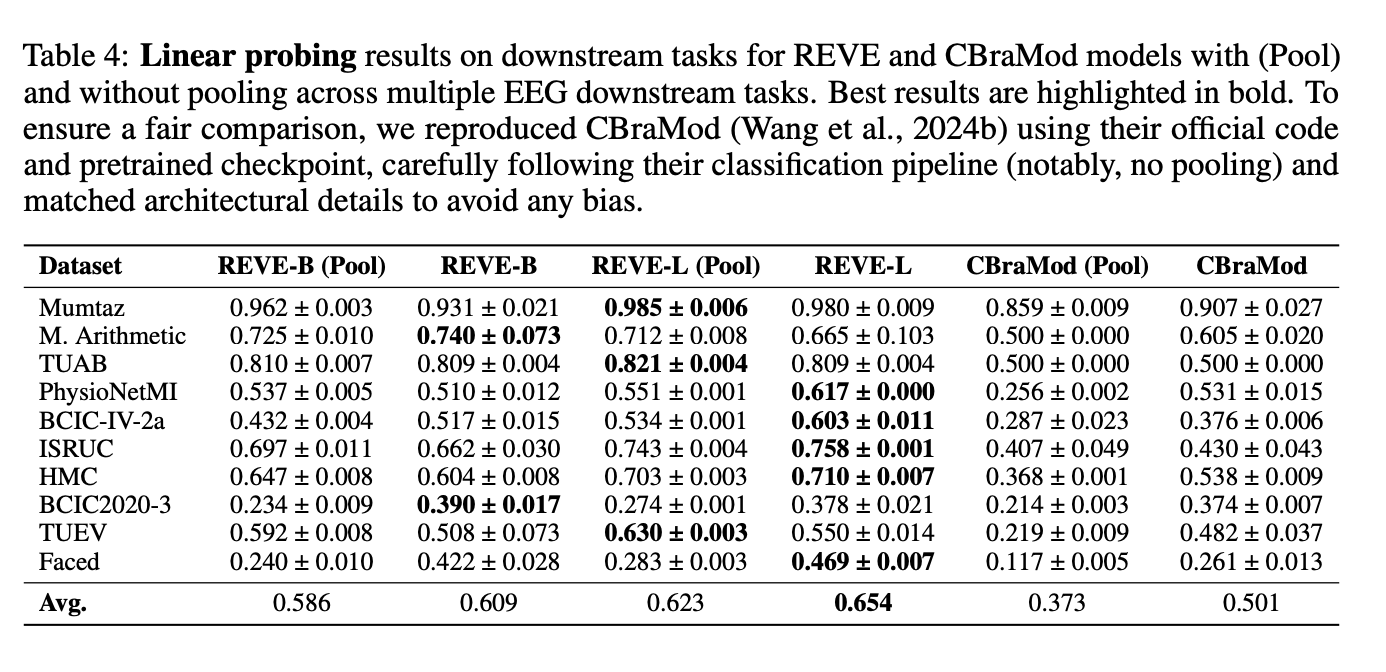
💡 나의 생각 (Critical Review)
- Strength: 서로 다른 전극 수에 대해 하나의 방식으로 처리할 수 있는 점이 눈여겨볼 만하다. 그리고 현재 EEG에서의 대규모 모델 학습 전략에 대해 많은 것을 배울 수 있었다.
- Next Step: PSG에 포함된 EEG와 ECG에 대해 적용해보면 좋을 것 같다. 느낌이 VCG랑 비슷한데도 서로 달라 적용해보면 좋을 것 같다.