머신러닝 교과서 1장 : 컴퓨터는 데이터에서 배운다
1장 : 컴퓨터는 데이터에서 배운다
연구실이나 학회, 그리고 다양한 수업에서 ML/DL을 다루다 보니, 내가 알던 지식들이 너무 중구난방이라는 것을 깨닫게 되었고, 이번 기회에 정리해보고자 한다.
사용할 자료는 머신러닝 교과서 파이토치편이고, 많은 내용을 한번 제대로 정리해보고 싶어서 해당 교재를 고르게 되었다. 또한 정리는 기존에 내가 잘 몰랐던 내용이나 중요한 내용을 위주로 간략히 정리하고자 한다.
머신러닝의 세 가지 종류
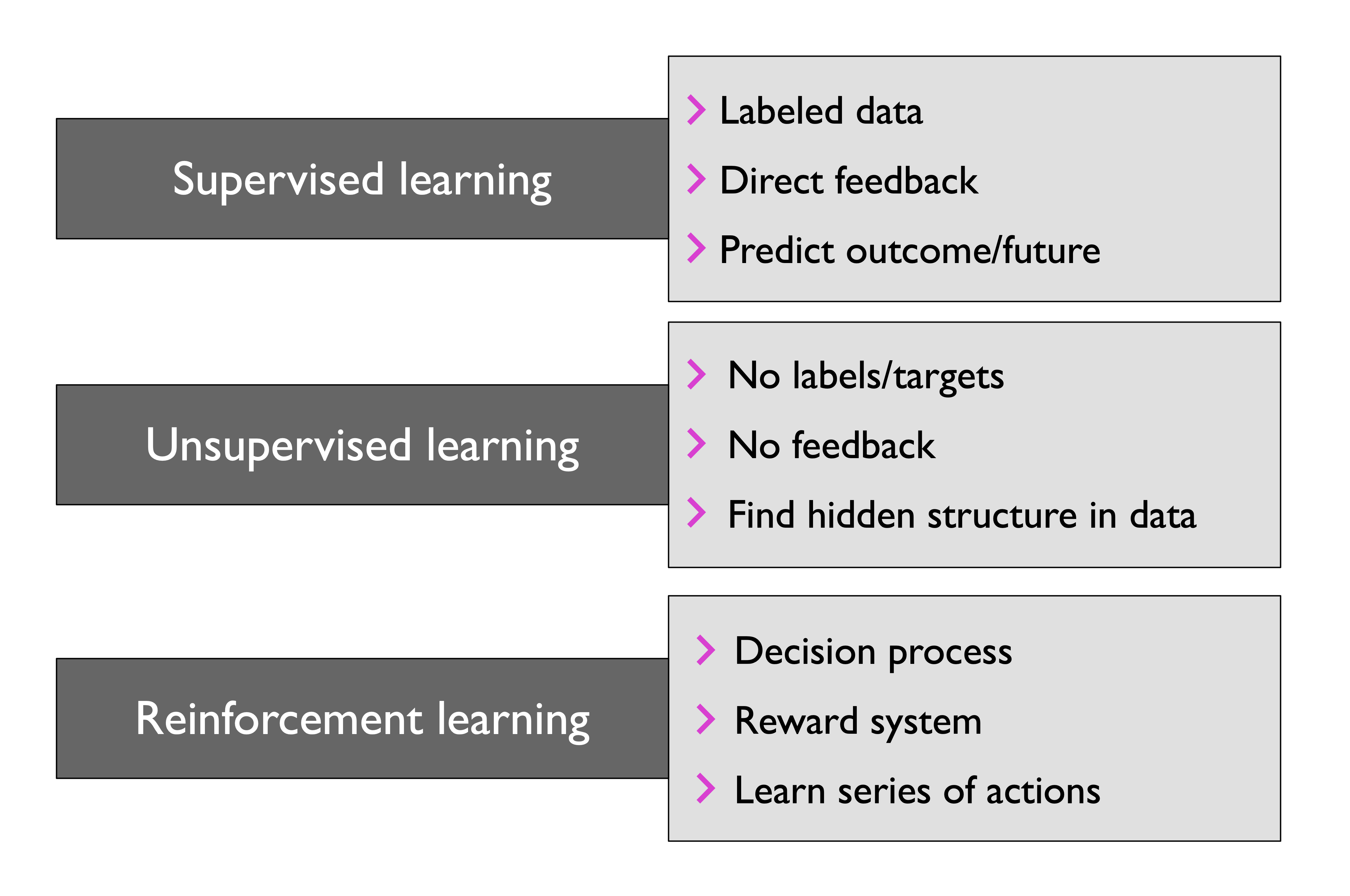
- Supervised learning (지도학습) : label, 직접적인 feedback, 예측(및 출력)
- Unsupervised learning (비지도학습) : unlabel, feedback 없음, 데이터의 숨겨진 구조
- 📌 Reinforcement learning (강화학습) : 결과와 과정, 보상 시스템, 연속된 행동으로부터의 학습
지도학습
라벨링된 데이터를 train하여, 본 적 없는 데이터를 예측
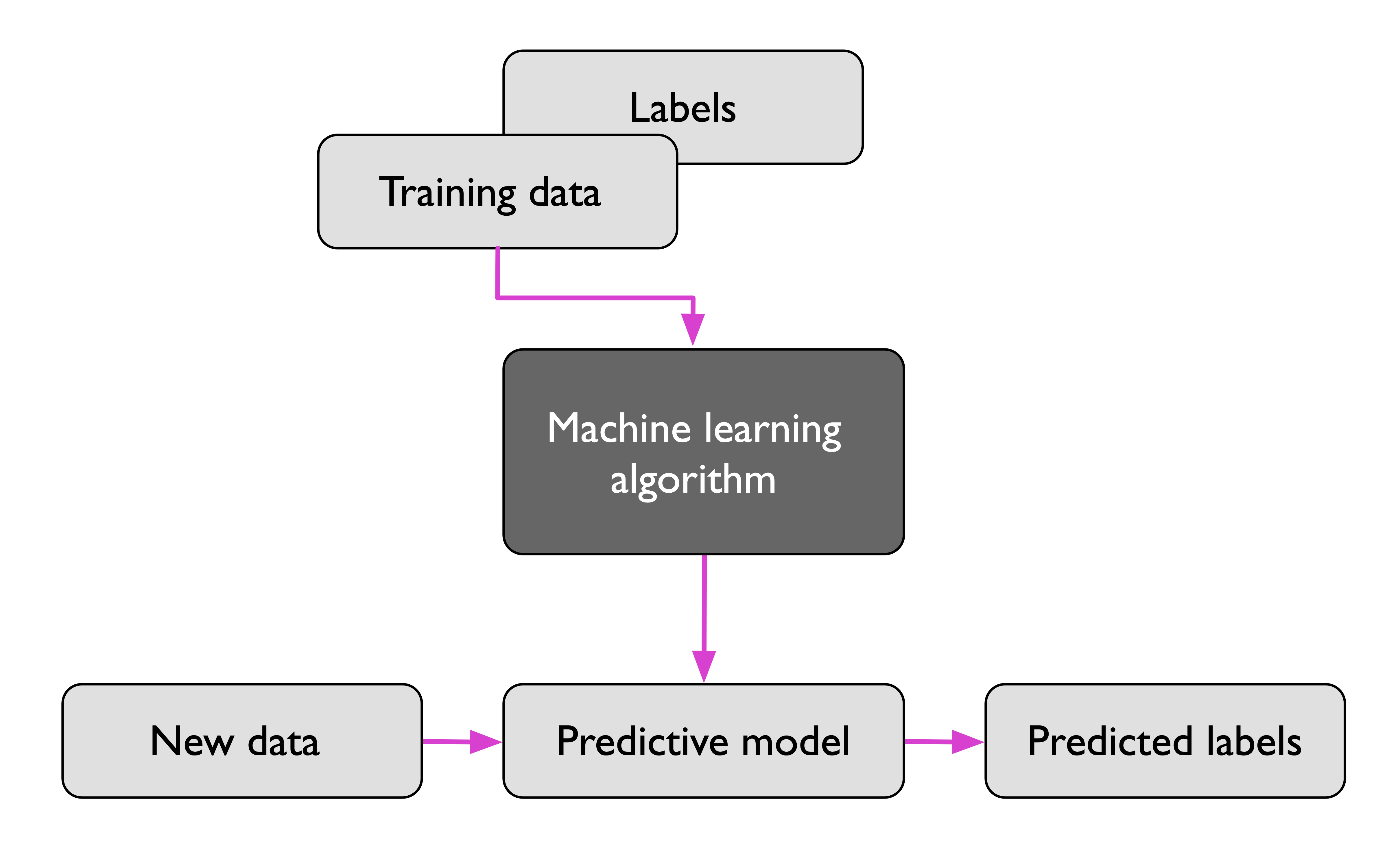
데이터와 레이블을 모델링하는 과정으로서, 레이블을 학습하는 방식이다. 지도학습에는 크게 2가지 문제가 있는데 회귀, 분류가 그것이다.
- 분류 : 개별(이산) class label을 예측
- 회귀 : 연속적인 값을 예측
Classification (분류문제)
과거의 관측(과거의 데이터)을 통해 새로운 샘플의 레이블을 예측한다.
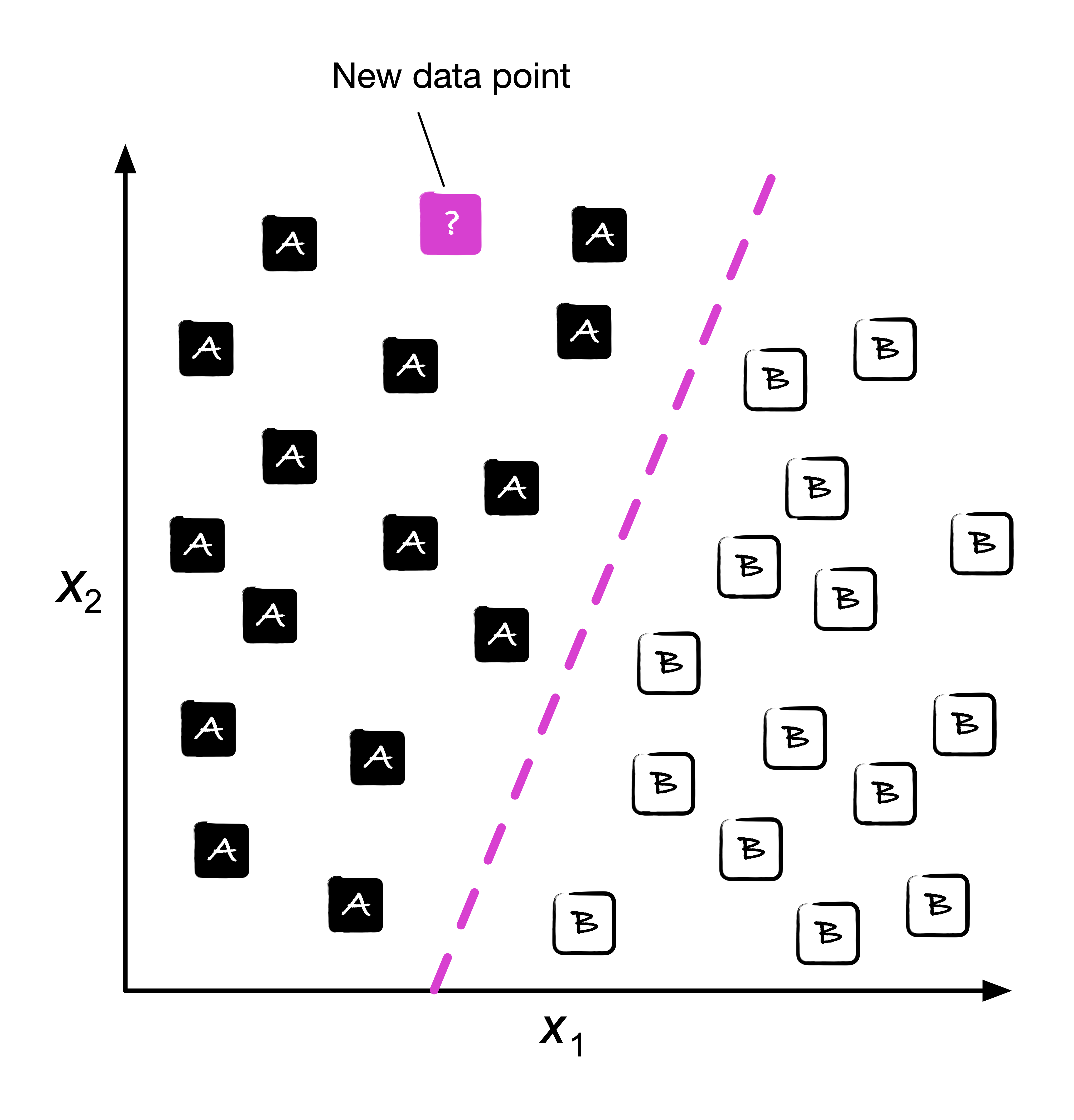
분류문제는 decision boundary (결정경계)를 바탕으로 class를 예측하는 문제이다. 2개의 class를 분류하는 이진 분류 문제와, n개 이상의 class를 분류하는 다중분류 문제가 있다.
Regression (회귀문제)
예측변수(predictor variable, feature)와 반응변수(response variable, target)를 바탕으로 두 변수 사이의 관계를 학습한다.
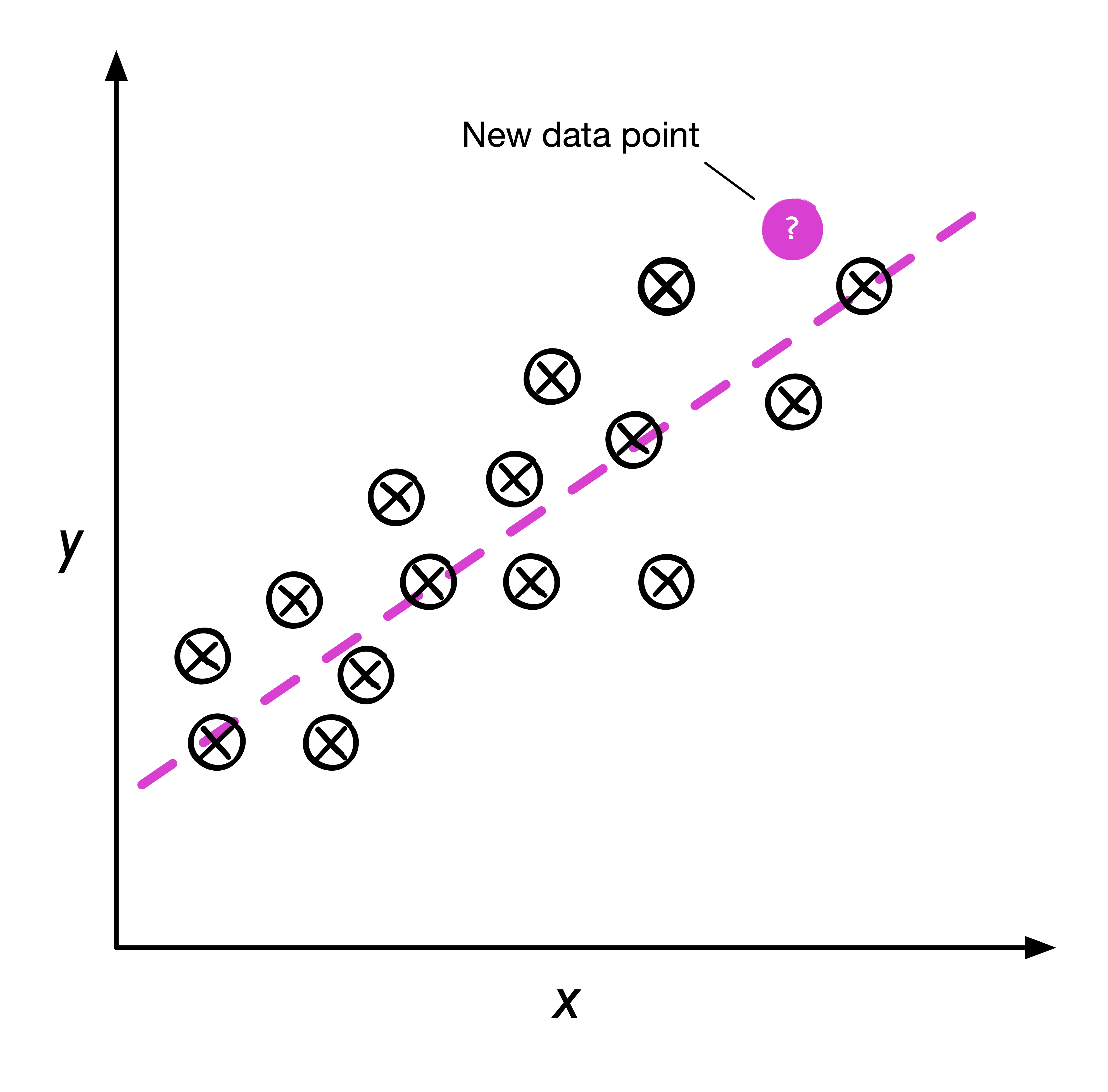
[!NOTE] 이전부터 들던 생각인데, 분류나 회귀나 같은 문제인 것 같다. 미지의 샘플에 대해 이산적인 값이나 class를 예측한다거나(분류문제), 연속적인 값을 예측하는 것은 동일한 부분이니까 말이다. 사실 많은 문제를 생각할 때 이게 분류문제인지 회귀문제인지를 고민했었고, class 예측 == 분류, 이외는 회귀라고 결론을 내린 적이 있었다. 근데 이게 의문이 들었던 게 분류문제를 회귀로 푸는 방식 때문이었다. 연구실에서 유전자 관련 문제를 풀고 분명히 분류문제(어떤 단백질이 발현)인데 이걸 회귀로 접근해서 학습시키는 방식을 교수님께서 알려주셨기 때문이다. 이 내용을 보기 전까지만 해도 복잡했는데, 사실 같은 문제가 아닌가 싶다.
강화학습
환경과 상호작용하여 시스템 (agent)의 성능 향상을 목적으로 한다
강화학습은 현재 상태에 대한 보상을 포함한 환경과, 시스템의 상호작용을 학습시킴으로써, agent는 보상이 최대화되는 일련의 행동을 학습한다.
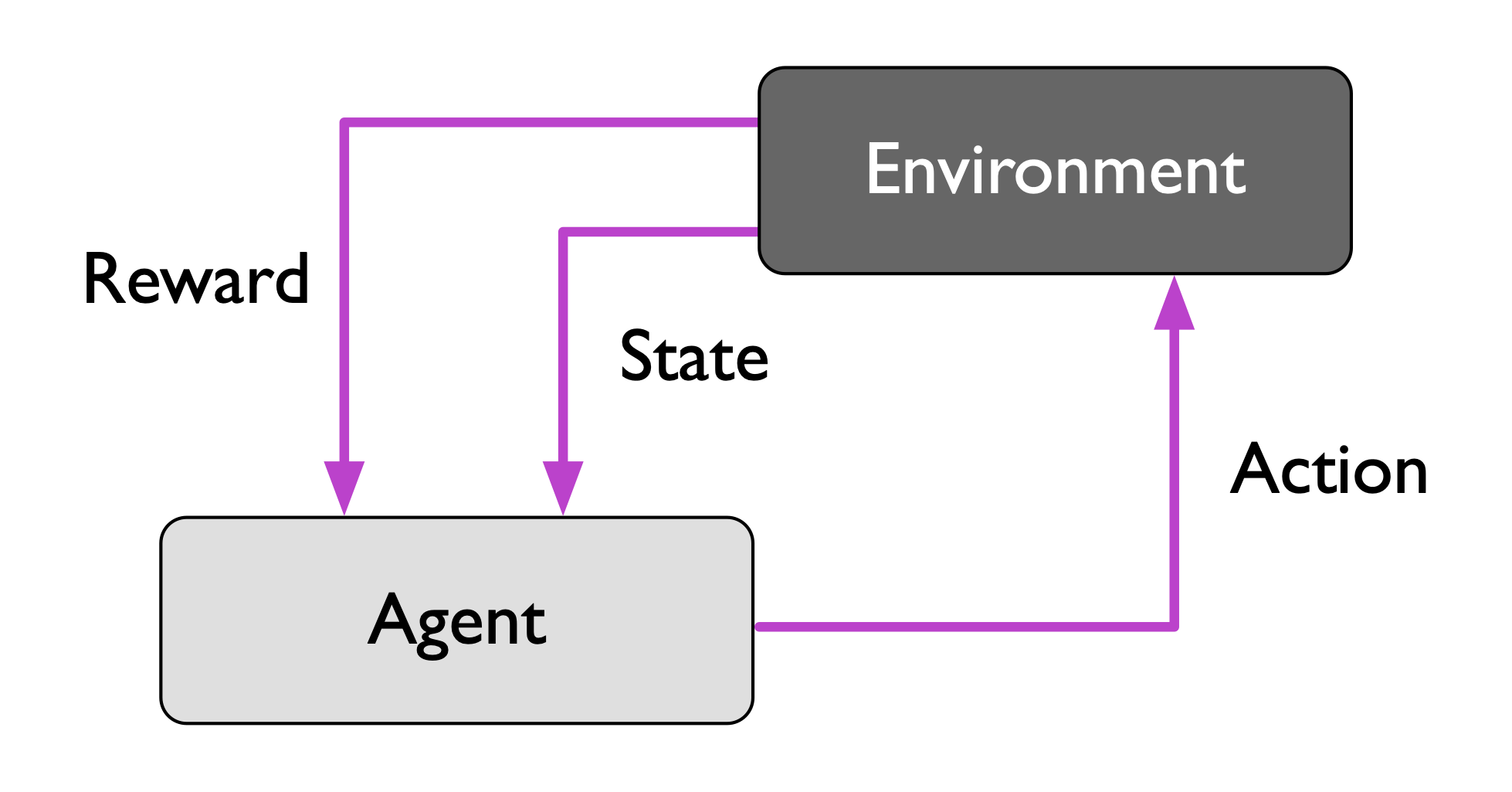
특히 이 보상이 지도학습의 정답과 혼동될 수 있다. 강화학습의 보상이란 답이 아니라 행동이 얼마나 좋은가를 함수로 측정한 값이다. 또한 각 상태는 양 또는 음의 보상을 가지고 있다. 이러한 보상을 얻기 위해서 탐험적인 시행착오(trial and error)나 세부적인 계획을 사용한다.
이 교재에서는 체스를 예로 들었다.
- 환경 : 체스판의 상황
- 보상 : 승/패
agent는 기물 이동의 결과를 통해 보상을 획득하게 되며 이동 시 다양한 환경 상태에 놓이게 된다. 이때 강화학습의 목표인 시스템의 보상이 최대화되어야 한다를 다시 상기해보자. 보상을 최대화하는 것이기 때문에 중간 과정은 생략된다. 즉 보상은 게임이 끝날 때까지 제공되지 않는다는 점에 주목할 필요가 있다.
예를 들어 체스에서 가장 강한 기물인 퀸을 잡히면 승률이 떨어지는 것은 당연하다. 반대로 내가 상대의 기물을 잡으면 승률이 높아지는 것은 자명하다. 그러나 체스 전술 중 퀸 희생 전략이 있다. 아라비안 메이트 같은 상황에서 퀸을 포기하고 나이트와 룩으로 체크메이트를 하는 경우에는 승리하게 된다. 즉 양의 보상을 받을 수 있다. 강화학습이란 이러한 행동을 학습하고 피드백하여, 전체 보상을 최대화하는 것을 목표로 한다.
비지도학습
의미 있는 정보를 추출하여 data의 구조를 탐색하는 학습 기법이다.
클러스터링
EDA나 패턴을 발견하는 기법이다.
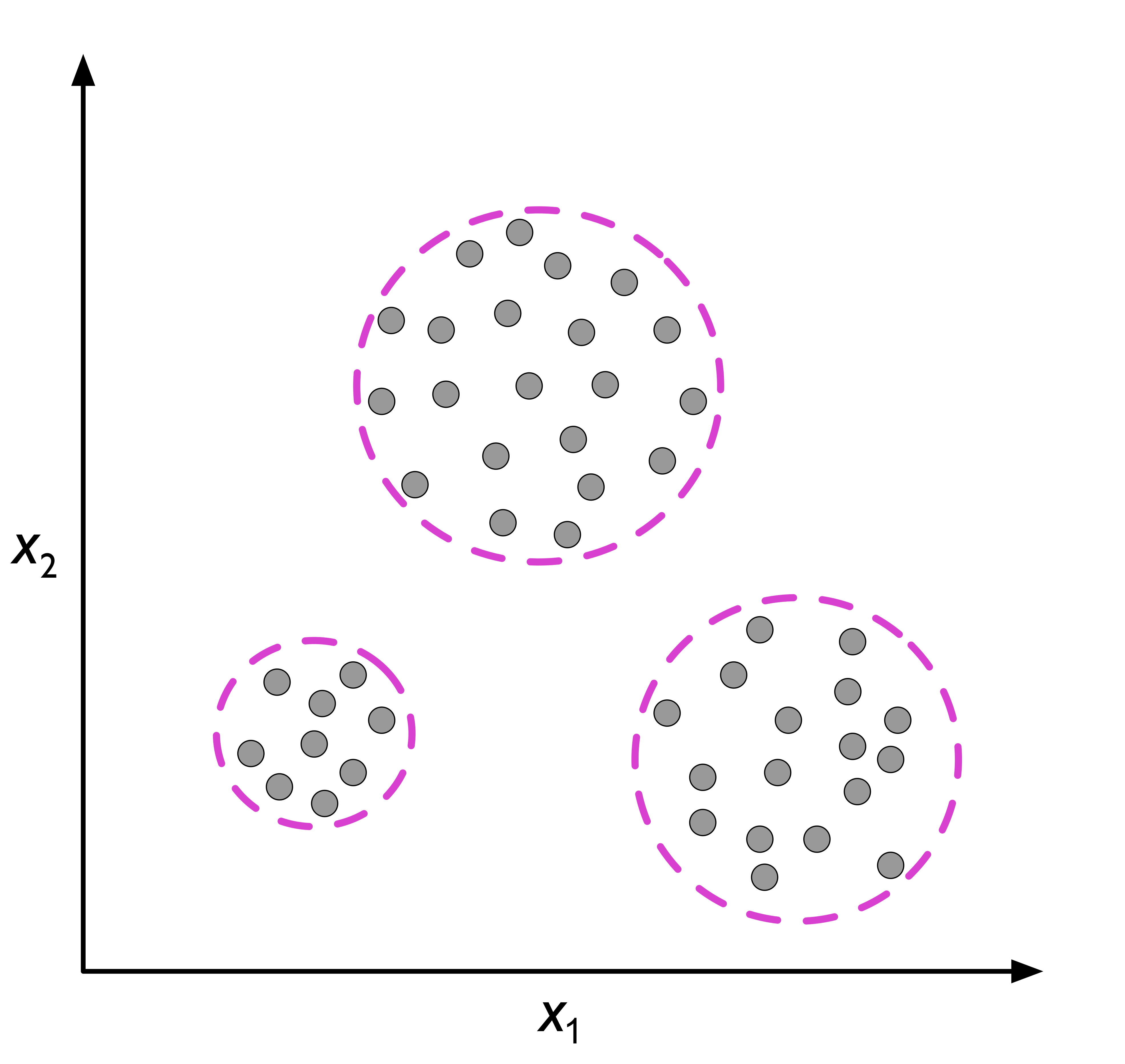
특히 unsupervised classification이라고도 불리는데, 그 이유는 각 군집을 만들어 정보를 조직화하고 데이터의 관계를 유도하여 class(군집)를 만들기 때문이다. 즉 그룹 소속에 대한 사전 정보 없이 군집을 만드는 기법이라 생각하면 좋다.
차원 축소
고차원의 데이터의 노이즈를 제거하여 subspace(저차원)로 옮기는 방법이다. 노이즈 제거에도 탁월하지만, 시각화에도 많이 사용한다.
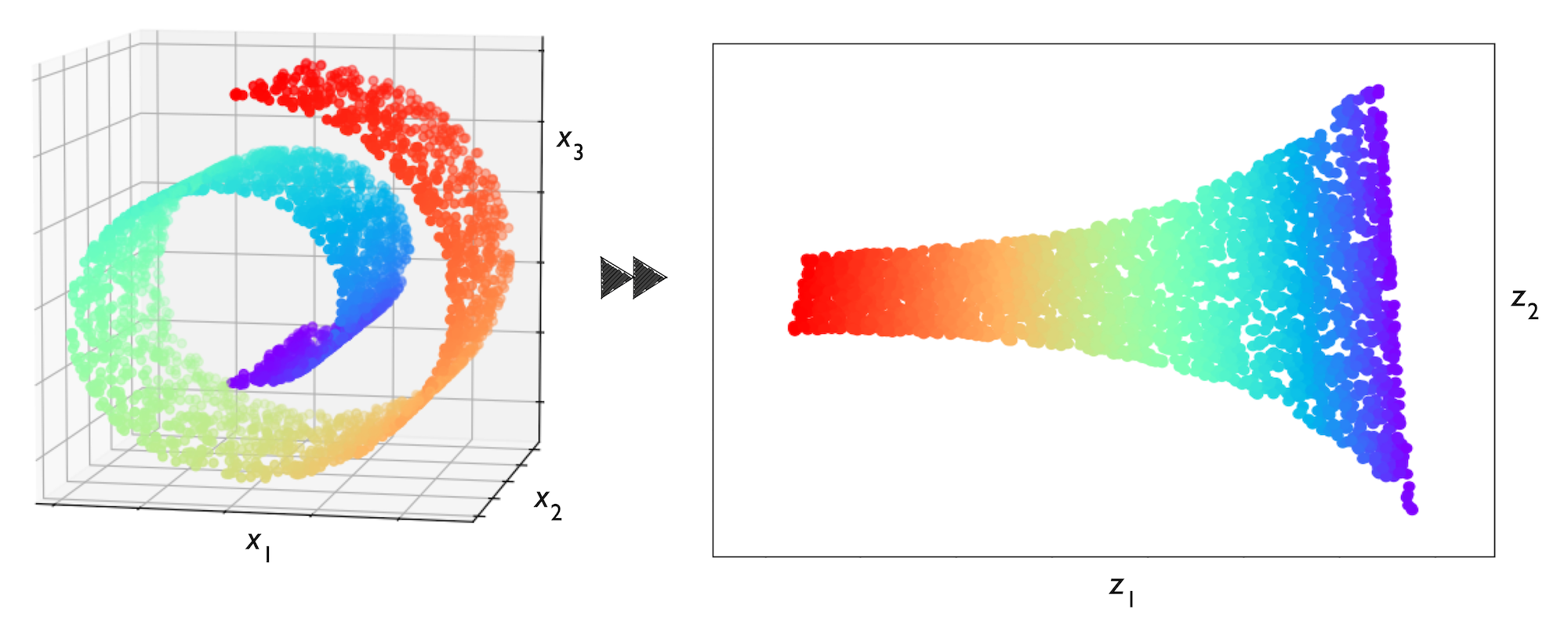
특히 노이즈를 제거하여 알고리즘의 성능 향상에 기여하는 경우도 종종 있다. 차원 축소의 경우 복잡도(공간, 시간)를 낮추는 데 의의를 두게 되는데, 가끔 성능이 향상하는 이유는 데이터의 feature 간 상관이 너무 높아 중복 정보를 제거하는 경우, SNR(Signal-to-Noise Ratio)이 낮은 경우(관련 없는 특성이나 노이즈가 많은 경우) 성능 향상에 기여하기 때문이다.
[!NOTE] 사실 강화학습은 배워본 적 없기 때문에 기초적인 내용만 알아봤는데도 생각보다 흥미롭다. 특히 요즘 많은 모델들이 학습 이후 강화학습을 추가로 적용하는 경향이 있는데, 더 자세히 알아보고 싶다.
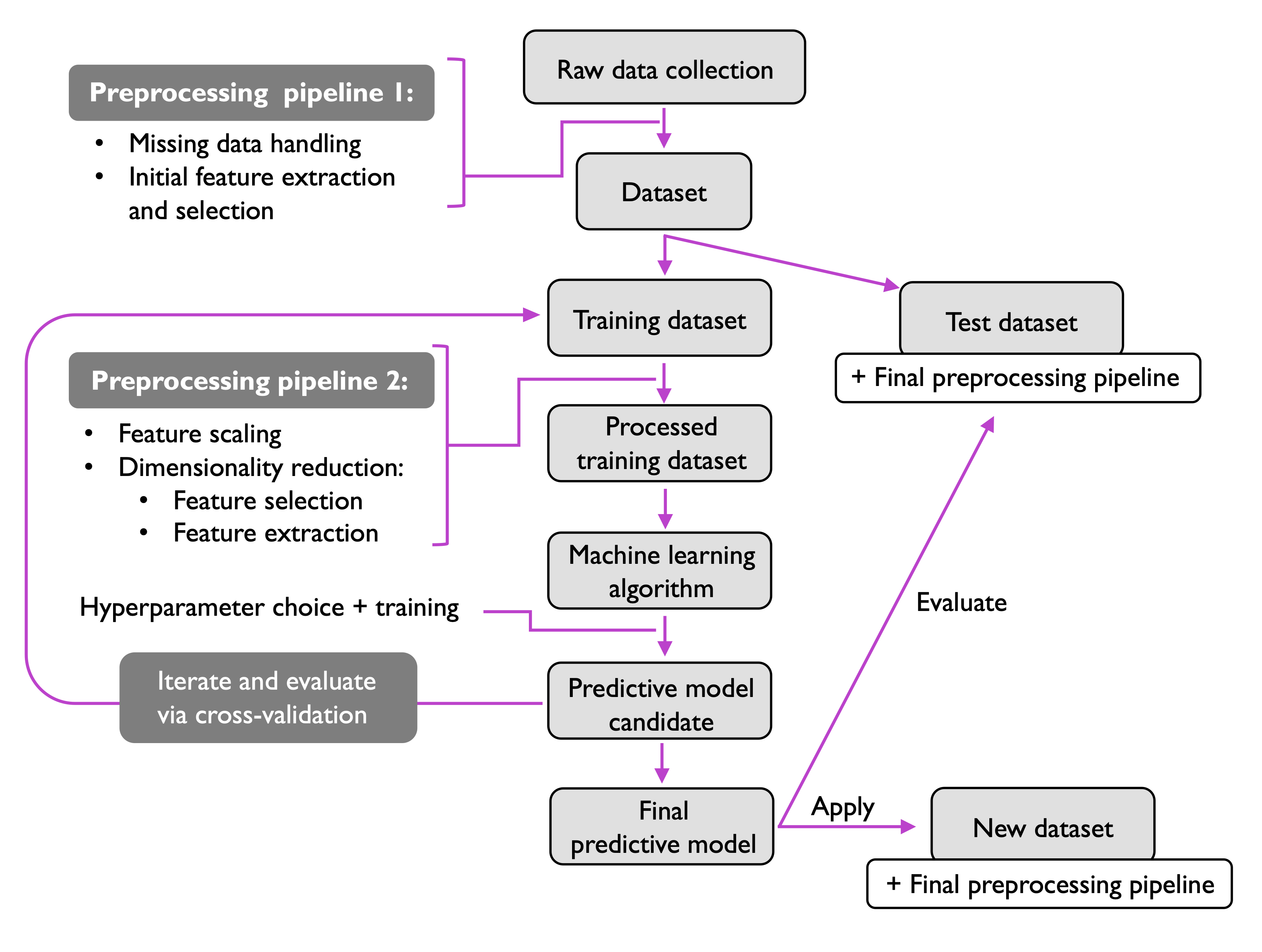
머신러닝 Pipeline
간략한 머신러닝 파이프라인을 아래에 첨부하고 오늘은 그만 마치도록 하겠다. 추가적으로 모든 분류 모델들은 태생적인 bias가 있다는 점 또한 기억할 만하다.